如何对足球比赛结果进行预测和投注实现盈利?
这一主题的学术文献参见最后的参考资料。这些文献都在试图说明其所使用的预测方法可以实现盈利,然而实际是否如此有待检验。
一个更关键的问题是,这些文献没有从理论上讲明白需要达到怎样的预测程度才能实现盈利。本文将给出实现盈利的预测条件。
另一个反过来的问题是,如何通过盈利评估确定哪一个预测模型更好。直接对各种预测模型的收益率进行比较是不可取的大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!。这是因为只有在给定投注赔率和投注策略的前提下,不同预测模型的收益率才可以进行比较。到目前为止,学术文献中还欠缺一个从收益率的角度对各种预测模型进行比较的方法,而本文将提出一个可行的方法。
声明:本文作者仅进行理论分析,不对任何实际操作结果负责。
假设某场比赛某种结果出现概率为p,对应赔率为b,则对这一结果进行投注的收益期望为:

例如,p=0.5, b=3,则E(r)=0.5,即本金为1,收益期望为0.5,最终本金变为1.5。收益期望pb-1又叫做利润率(edge)。
由收益期望的定义可知,对某一种比赛结果进行投注的收益与概率和赔率有关,而同一场比赛不同比赛结果有不同的概率和赔率,因此对某一场比赛进行投注的收益还与投注策略有关:即选择哪一个比赛结果。
因此,对比赛结果进行投注的收益与三个要素有关:概率、赔率和投注策略。
当给定概率和投注策略时,赔率越大,收益期望越大。因此,在条件允许的情况下,应选择各家博彩公司的最高赔率。而当给定概率和赔率时,投注策略为投注收益期望最高且大于0的比赛结果,而不是投注概率最大的比赛结果。
可以看到,给定概率后,选择赔率和确定投注策略存在确定的方案。因此,确定比赛结果的概率是确保盈利最重要的前提。无论如何确定概率,对概率的准确性进行评估总是必要的,因为概率估计的误差会导致收益期望估计也存在误差。通用的评估方法为使用测试数据。
假设测试数据有n场比赛,使用某种投注策略对这n场比赛进行预测的收益期望为  大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!。收益期望大于0的充分条件为每一场比赛的收益期望都大于0,即对任意i,都有
大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!。收益期望大于0的充分条件为每一场比赛的收益期望都大于0,即对任意i,都有  。由这一条件可得推论:
。由这一条件可得推论:

又这n场比赛的预测准确率  ,其中
,其中  ,0意味着第i场比赛预测错误,1意味着第i场比赛预测正确。每场比赛预测正确的概率为
,0意味着第i场比赛预测错误,1意味着第i场比赛预测正确。每场比赛预测正确的概率为  ,则
,则  ,所以上述推论又可表述为:
,所以上述推论又可表述为:

当n较大时,E(a)可用a来估计,因此:

记做在某种投注策略下的模型预测准确率大于对应赔率倒数的平均值。注意这一实现盈利的条件在数学上既非充分也非必要,但从实际数据来看,这一条件可以很好地将模型预测准确率与盈利联系起来,为模型的改进确定方向。
若要确保盈利,则条件可改为:模型预测准确率95%置信区间的下限大于预测结果对应赔率倒数的平均值。预测准确率的置信区间可由自助法(bootstrap)得到。
前面的讨论还剩下一个问题,那就是如何通过预测模型的盈利评估对不同模型进行比较和选择,从而确定更好的预测模型。
直接对各种预测模型的收益率进行比较是不可取的。这是因为只有在给定投注赔率和投注策略的前提下,不同预测模型的收益率才可以进行比较。投注策略还比较容易统一,而使用相同的赔率数据却并不简单。不同研究预测的比赛及其对应的赔率不尽相同,即使同样的比赛也可能会使用不同博彩公司的赔率。
到目前为止,学术文献中还欠缺一个从收益率的角度对各种预测模型进行比较的方法。本文将提出一个可行的方法,这涉及到对赔率的性质更多的认识。所以接下来先谈一下赔率的性质,再提出通过盈利评估比较预测模型的方法。
首先简单介绍一下赔率。2007年12月8日,阿森纳在英超联赛中主场迎战富勒姆。博彩公司BET365开出的赔率组合是:阿森纳获胜,赔率1.33;两队打平,赔率4.5;客队富勒姆获胜,赔率10。这些数字意味着什么呢?
假设比赛前押1元猜主队阿森纳获胜,而最终比赛结果确实是主队获胜,那么就能赢回1.33元。扣除押的1元,那么盈利就是0.33元。如果比赛结果是双方打平,或者客队胜,那么就输掉了押的1元钱。剩下两个赔率类似,代表押对结果博彩公司会返回的钱。扣除本金1元,获得的盈利分别为3.5元和9元。
博彩公司制定赔率的要点在于:无论出现什么样的比赛结果,博彩公司都能赚钱。由此得出赔率的第一条性质:性质1:  ,其中f为某种比赛结果的(资金)投注比例,b为对应的赔率。
,其中f为某种比赛结果的(资金)投注比例,b为对应的赔率。
下面证明这一性质。
以上面提到的阿森纳对阵富勒姆的比赛为例。假设在全体彩民中,押阿森纳获胜的投注比例是  ,对应博彩公司开出的赔率是
,对应博彩公司开出的赔率是  ;押两队打平的比例是
;押两队打平的比例是  ,对应博彩公司开出的赔率为
,对应博彩公司开出的赔率为  ;押富勒姆获胜的比例是
;押富勒姆获胜的比例是  ,对应博彩公司开出的赔率为
,对应博彩公司开出的赔率为  。容易知道,所有结果的投注比例之和为1:
。容易知道,所有结果的投注比例之和为1:

如果最终比赛结果是阿森纳赢,那么博彩公司的收益为(假设总的投注额为1):

博彩公司只要能够保证这一收益大于0即可:  。同样地,若比赛结果是双方打平或者富勒姆获胜时,博彩公司需保证下面两个不等式成立才能赚钱:
。同样地,若比赛结果是双方打平或者富勒姆获胜时,博彩公司需保证下面两个不等式成立才能赚钱:  。因此,为了保证出现任何比赛结果都能赚钱,博彩公司一定会设置适当的赔率满足上述不等式。性质1推论:
。因此,为了保证出现任何比赛结果都能赚钱,博彩公司一定会设置适当的赔率满足上述不等式。性质1推论:  ,其中
,其中  为某博彩公司为事件i开出的赔率,且各事件之间两两互斥。对于足球比赛胜平负预测来说,
为某博彩公司为事件i开出的赔率,且各事件之间两两互斥。对于足球比赛胜平负预测来说,  。
。
这一推论的证明从略,其正确性可由实际赔率数据进行检验。性质2:当有多个博彩公司对同一场比赛开出赔率时,取各家赔率中的最大值,则  ,即
,即  ,最大赔率的倒数可以认为是彩民对比赛结果的概率估计。
,最大赔率的倒数可以认为是彩民对比赛结果的概率估计。
由赔率的性质2,本文提出通过盈利评估比较预测模型的统一前提:确定某种投注策略,赔率数据则选择所有博彩公司的最大赔率。
由赔率的性质2可得,选择最大赔率实质上是将预测模型的概率估计与彩民对比赛结果的概率估计进行比较,这就为比较不同预测模型建立了一个统一的比较基线。模型的预测与这条基线的正向偏离越大,收益也就越高。
接下来将实际建立预测模型,用前面提到的方法对预测模型进行盈利评估,并确定预测模型所做的预测是否能够实现盈利。建模的全部过程参见本文最后数据分析笔记/代码的链接。
由前面的讨论可知,预测模型的概率估计与彩民对比赛结果的概率估计之间的差异将决定收益率。因此一个猜想是:若使用一些普遍能够想到的数据作为特征变量,其与彩民对比赛结果的估计会很接近,造成收益率不高。若使用一些不太常见的数据作为特征变量,所做的估计可能会与彩民的估计有差异。
下面将比较三组不同的特征变量建立的预测模型:常见特征数据、不常见特征数据、常见特征数据+不常见特征数据。
常见特征数据有:进球数、场均积分和联赛相对排名。
不常见特征数据包括其他数据类型,比如犯规数、角球数、红黄牌数等等。
主要结果总结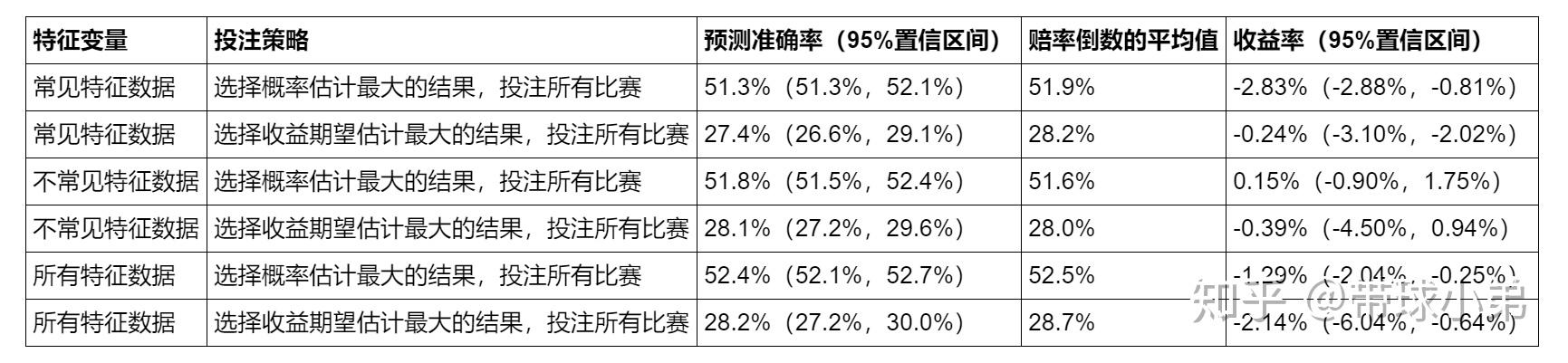
上述结果有以下结论:预测准确率本身不能决定收益率,但预测准确率与赔率倒数的平均值之差与收益率正相关。所以本文建立的实现盈利的预测条件 是实践可行的。当采取选择概率估计最大的投注策略时,使用常见特征数据的收益率最差。这印证了之前的猜测:使用普遍能够想到的数据作为特征变量,会造成预测模型的估计与彩民的估计接近,造成收益率不高。而使用不常见特征数据的收益率达到了0.15%,是唯一一个正收益率。因此,应该使用不太常见但又影响比赛结果的数据作为特征数据进行预测,才能获得收益。由此出发,本文猜测,使用球队赛前的心理状态和疲劳程度等信息更新球队实力的方法应该是可行的。由同一组特征变量建立的预测模型,采取选择收益期望估计最大的投注策略并没有优于选择概率估计最大的投注策略。这再一次说明了良好的概率估计才是盈利最重要的前提。尽管使用不常见特征数据建立的预测模型+采取选择概率估计最大的投注策略的收益率为0.15%,但收益率95%置信区间的下限为-0.9%,仍然小于0。因此严格意义上讲,这种情况仍未能确保盈利。大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
投注策略推广
除了简单地采取选择概率估计最大和选择期望估计最大的投注策略外,还可以通过  的差值对投注比赛进行筛选。不满足
的差值对投注比赛进行筛选。不满足  的比赛将不作为投注对象。这样的投注策略理论上可以提高收益率,当然前提仍然是良好的概率估计。在这一维度得到的结果可以得出更多的结论。常见特征数据+选择概率估计最大的结果
的比赛将不作为投注对象。这样的投注策略理论上可以提高收益率,当然前提仍然是良好的概率估计。在这一维度得到的结果可以得出更多的结论。常见特征数据+选择概率估计最大的结果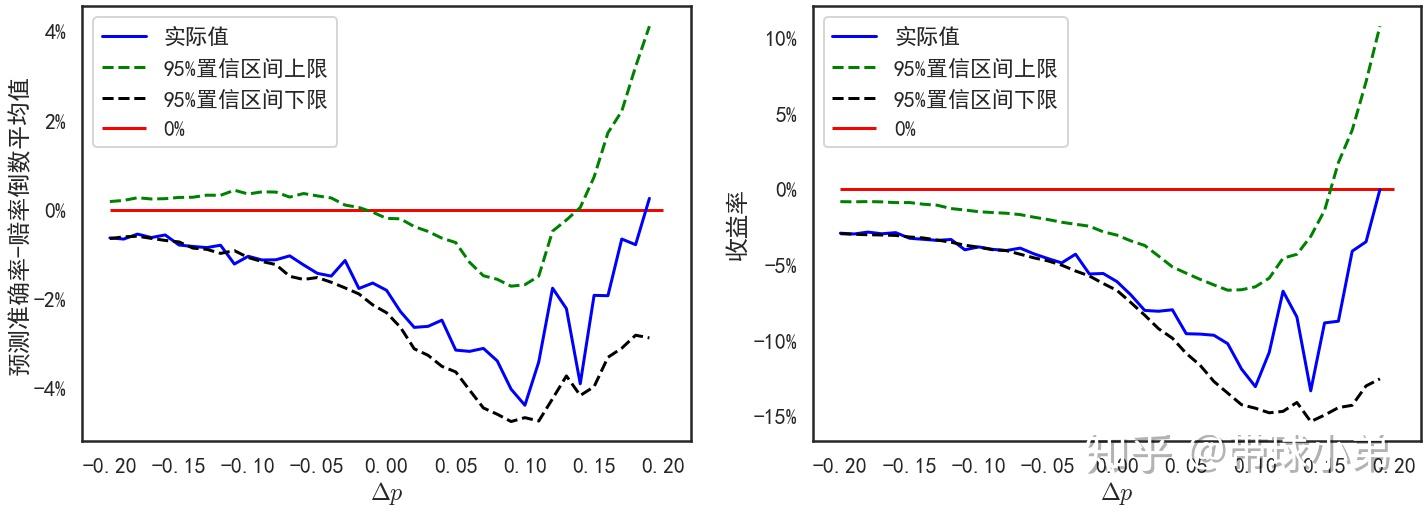
左侧图为预测准确率与赔率倒数平均值之差,右侧图为收益率。蓝线为实际估计值,绿线为95%置信区间上限,黑线为95%置信区间下限。红线为基准值0。
这张图再次说明了预测准确率与赔率倒数的平均值之差与收益率正相关。其次随着 的增加,收益率并不是提高而是降低。这说明,在这种情况下,通过 对投注比赛进行筛选的策略并不能提高收益率。常见特征数据+选择收益期望估计最大的结果 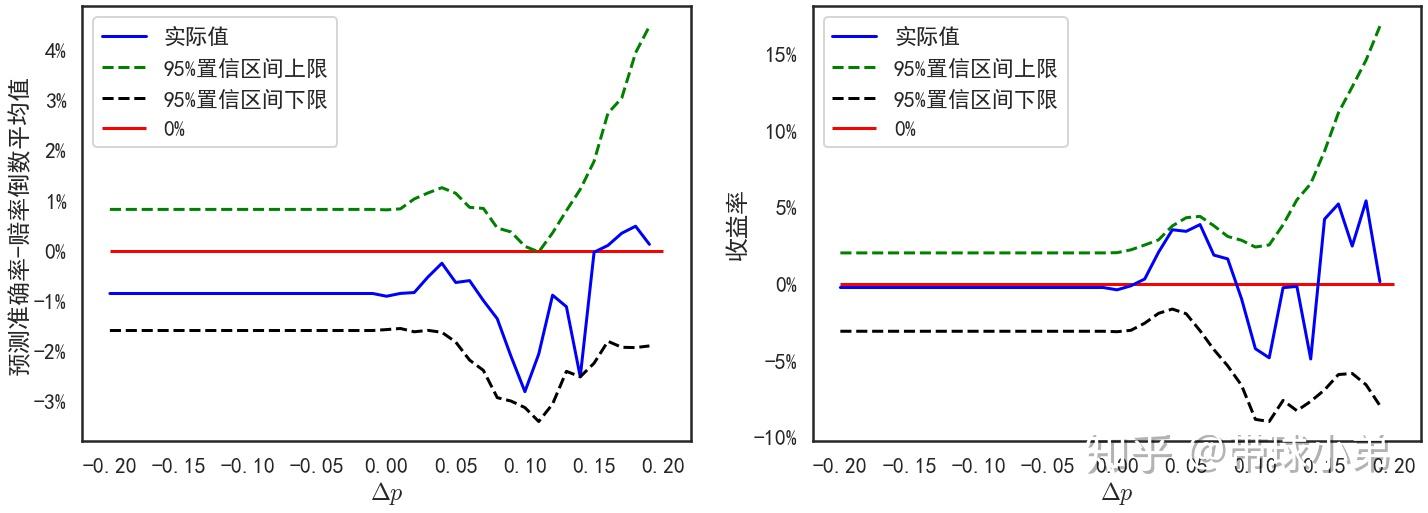
当  时,收益率为4%。这应该是一个不错的盈利条件,当然按照严格的标准,其95%置信区间下限仍未大于0,无法确保盈利。不常见特征数据+选择概率估计最大的结果
时,收益率为4%。这应该是一个不错的盈利条件,当然按照严格的标准,其95%置信区间下限仍未大于0,无法确保盈利。不常见特征数据+选择概率估计最大的结果 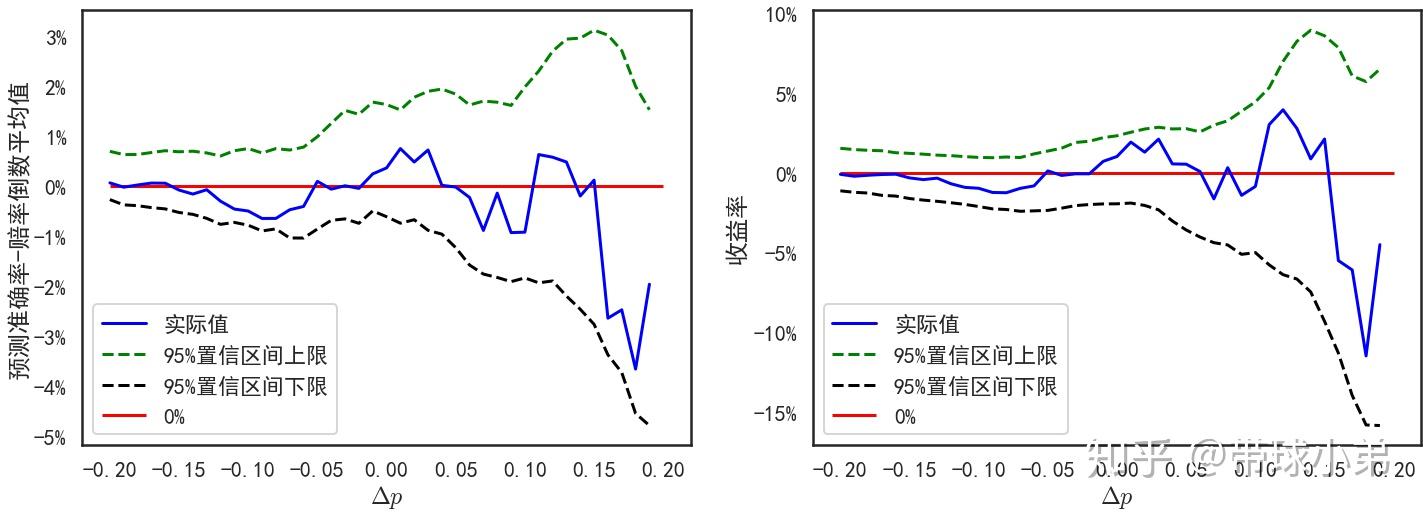
最好的盈利条件应该为:当 时,收益率为2%。当然同样无法确保盈利。
其他情况都没有比较好的盈利条件,就不详细讨论了。要想对足球比赛胜平负结果进行投注实现盈利,模型预测准确率应大于对应赔率倒数的平均值。预测准确率本身不能决定收益率。使用所有博彩公司的最大赔率为预测模型进行收益评估可以为比较不同预测模型的收益率建立统一的比较基线。在特定条件下,使用本文建立的预测模型进行投注收益率大于0。为进一步提高收益率使得收益率95%置信区间的下限大于0,应使用不太常见但又影响比赛结果的信息对比赛进行预测,避免使用场均进球数等常见数据。
参考资料
数据分析笔记/代码:https://github.com/xzl524/football_data_analysis/blob/master/notebooks/predict_football_match_outcome.ipynb
Constantinou., Anthony Costa. 2013. “Bayesian Networks for Prediction, Risk Assessment and Decision Making in an Inefficient Association Football Gambling Market.” Thesis, Queen Mary University of London. https://qmro.qmul.ac.uk/xmlui/handle/123456789/8404.
Dixon, Mark J., and Stuart G. Coles. 1997. “Modelling Association Football Scores and Inefficiencies in the Football Betting Market.” Journal of the Royal Statistical Society: Series C (Applied Statistics) 46 (2): 265–80. doi:10.1111/1467-9876.00065.
Goddard, John, and Ioannis Asimakopoulos. 2004. “Forecasting Football Results and the Efficiency of Fixed-Odds Betting.” Journal of Forecasting 23 (1): 51–66. doi:10.1002/for.877.
Rue, Håvard, and Øyvind Salvesen. 2000. “Prediction and Retrospective Analysis of Soccer Matches in a League.” Journal of the Royal Statistical Society. Series D (The Statistician) 49 (3): 399–418. https://www.jstor.org/stable/2681065.










评论留言